
Introduction
The rapid evolution of artificial intelligence (AI) has led to the development of sophisticated application architectures that are transforming industries. As software engineers, cloud architects, and AI/ML engineers, understanding these architectures is critical for building scalable, efficient, and high-performing AI solutions. This blog post delves into the emergent AI application architecture, focusing on the design pattern of pre-training > training > pre-inferencing > post-inferencing. We will explore the flow of data through this design pattern, the steps of manipulation involved, and how solutions architects can optimize each stage.
Understanding the Design Pattern
Pre-Training
Pre-training is the foundational phase where the AI model is initially exposed to vast amounts of data. This phase involves preparing the data, which includes data collection, cleaning, annotation, and critical considerations around dataset quality and ethical implications.
- Data Collection:
- Identify the problem and gather relevant data from diverse sources.
- Ensure data is representative of the tasks the model will perform.
- Consider multi-modal data collection for more robust models.
- Implement data versioning and lineage tracking for reproducibility.
- Dataset Characteristics:
- Sample Size: Determine appropriate dataset size based on model complexity and task requirements.
- Population Representation: Ensure the dataset reflects the diversity of the target population.
- Class Balance: Address imbalanced datasets through techniques like oversampling or undersampling.
- Temporal Aspects: Consider time-series data and potential concept drift.
- Data Preprocessing:
- Clean the data by removing duplicates and handling missing values.
- Standardize formats and apply normalization techniques.
- Implement feature engineering to create meaningful inputs for the model.
- Develop robust data pipelines for scalable and repeatable preprocessing.
- Bias Screening and Mitigation:
- Conduct thorough analysis to identify potential biases in the dataset.
- Implement bias mitigation techniques such as reweighting or adversarial debiasing.
- Use fairness metrics to evaluate and monitor bias throughout the AI lifecycle.
- Regularly audit datasets for emerging biases or shifts in data distribution.
- Ethical Considerations:
- Ensure data collection and usage comply with relevant privacy regulations (e.g., GDPR, CCPA).
- Obtain proper consent for data use and implement robust data anonymization techniques.
- Consider the potential societal impact of the AI system and mitigate negative consequences.
- Establish an ethics review board to oversee data practices and model development.
- Data Quality Assurance:
- Implement data validation checks to ensure consistency and integrity.
- Use statistical methods to detect outliers and anomalies in the dataset.
- Develop a systematic approach for data labeling and annotation, including inter-annotator agreement metrics.
- Regularly update and refresh datasets to maintain relevance and performance.
By incorporating these comprehensive pre-training strategies, you can establish a solid foundation for your AI model. This approach ensures not only the technical quality of your data but also addresses critical ethical and societal considerations, leading to more robust, fair, and responsible AI systems.
Training
Once the data is prepared, the training phase commences. This is where the model learns patterns from the data using various algorithms and frameworks. The choice of model, training technique, and optimization strategy can significantly impact the performance and efficiency of the final system.
- Model Selection:
- Task-Specific Models: Choose models tailored to specific tasks (e.g., BERT for NLP, ResNet for image classification).
- Multi-Modal Models: Utilize models that can handle multiple types of input data simultaneously.
- AutoML: Employ automated model selection tools to identify the best architecture for a given dataset.
- Model Routing and Arbitrage:
- Ensemble Methods: Combine predictions from multiple models to improve overall performance.
- Model Cascades: Implement a series of increasingly complex models, routing queries based on difficulty.
- Multi-Armed Bandits: Dynamically allocate resources to different models based on their performance.
- Optimization Techniques:
- Gradient Descent Variants: Explore advanced optimizers like Adam, RMSprop, or LAMB for faster convergence.
- Learning Rate Schedules: Implement adaptive learning rates to improve training stability and speed.
- Regularization: Use techniques like L1/L2 regularization, dropout, or batch normalization to prevent overfitting.
- Mixture of Experts (MoE):
- Sparse MoE: Train multiple specialized sub-models (experts) and a gating network to route inputs.
- Conditional Computation: Activate only relevant parts of the model for each input, improving efficiency.
- Dynamic Routing: Implement adaptive routing strategies that evolve during training.
- Advanced Training Paradigms:
- Federated Learning: Train models across decentralized devices or servers without exchanging raw data.
- Continual Learning: Develop models that can learn new tasks without forgetting previously learned information.
- Meta-Learning: Train models that can quickly adapt to new tasks with minimal fine-tuning.
- Hyperparameter Tuning:
- Bayesian Optimization: Use probabilistic models to efficiently search the hyperparameter space.
- Population-Based Training: Evolve a population of models, combining hyperparameter search with neural architecture search.
- Multi-Objective Optimization: Optimize for multiple competing objectives (e.g., accuracy, latency, and model size).
- Model Compression and Knowledge Distillation:
- Quantization-Aware Training: Train models with simulated quantization for better post-training quantization results.
- Progressive Knowledge Distillation: Gradually transfer knowledge from larger to smaller models during training.
By leveraging these advanced training techniques and strategies, you can develop highly optimized and efficient AI models that are well-suited to your specific use case and performance requirements. The combination of careful model selection, sophisticated training paradigms, and intelligent optimization approaches enables the creation of state-of-the-art AI systems capable of handling complex, real-world tasks.
Pre-Inferencing
In the pre-inferencing phase, the model is further optimized for real-time use. This step includes various techniques to enhance performance, reduce latency, and improve efficiency.
- Model Optimization:
- Quantization: Reducing the number of bits that represent weights to decrease model size and increase inference speed.
- Distillation: Training a smaller model to mimic a larger one, preserving performance while reducing computational requirements.
- Pruning: Removing unnecessary parameters to streamline the model without significant performance loss.
- Compilation: Using tools like ONNX or TensorRT to optimize the model for specific hardware.
- Fine-tuning:
- Domain Adaptation: Adjusting the model to perform well on specific domains or tasks.
- Few-shot Learning: Training the model to generalize from a small number of examples.
- Prompt Tuning: Optimizing input prompts to elicit better responses from the model.
- Retrieval-Augmented Generation (RAG):
- Traditional RAG: Enhancing model outputs by retrieving relevant information from external knowledge bases.
- Hybrid RAG: Combining retrieved information with the model’s inherent knowledge.
- Adaptive RAG: Dynamically adjusting retrieval strategies based on query complexity.
- GraphRAG:
- Knowledge Graph Integration: Incorporating structured knowledge graphs to enhance retrieval and reasoning.
- Multi-hop Reasoning: Enabling the model to traverse graph connections for complex query resolution.
- Graph Embedding: Using graph neural networks to create dense representations of knowledge structures.
- Caching and Indexing:
- Semantic Caching: Storing and reusing results for semantically similar queries.
- Vector Indexing: Creating efficient indexes for fast similarity search in high-dimensional spaces.
These advanced techniques significantly enhance model performance and efficiency, enabling more accurate and context-aware responses in real-time applications. The combination of model optimization, fine-tuning, and augmented retrieval methods creates a robust foundation for high-performance AI systems.
Post-Inferencing
Post-inferencing involves analyzing the results produced by the model and implementing feedback loops for continuous improvement. This phase is critical for ensuring that the model remains effective over time and delivers optimal results.
-
Feedback Loop: Collect feedback from users or systems and use it to further train and refine the model. This iterative process is essential for adapting to changing conditions and data distributions.
- Output Shaping: Implement strategies to guide the model’s output while maintaining flexibility:
- Use prompt engineering techniques to steer the model towards desired response formats.
- Implement templating systems for consistent output structures.
- Apply post-processing rules to ensure outputs adhere to specific guidelines or constraints.
- Guard Rails: Establish safeguards to prevent undesirable outputs:
- Implement content filtering to block inappropriate or harmful content.
- Use fact-checking mechanisms to verify critical information.
- Set up boundary conditions to keep outputs within acceptable ranges or topics.
- Chain of Thought Reasoning: Enhance model performance through step-by-step reasoning:
- Prompt the model to break down complex problems into smaller, manageable steps.
- Implement intermediate result validation to ensure each step in the reasoning chain is sound.
- Use this approach to improve transparency and debuggability of the model’s decision-making process.
- Output Diversity: Encourage varied and creative responses:
- Implement techniques like nucleus sampling or top-k sampling to introduce controlled randomness.
- Use prompts that encourage the model to consider multiple perspectives or solutions.
- Confidence Scoring: Develop mechanisms to assess the model’s confidence in its outputs:
- Implement probability thresholds for different types of responses.
- Use ensemble methods to compare outputs from multiple model versions or configurations.
- Continuous Evaluation: Set up ongoing performance monitoring:
- Regularly benchmark the model against a diverse set of test cases.
- Implement A/B testing for new model versions or inferencing strategies.
- Use metrics like perplexity, BLEU scores, or task-specific KPIs to track performance over time.
- Adaptive Learning: Implement systems for the model to learn from its interactions:
- Use reinforcement learning techniques to fine-tune the model based on successful interactions.
- Implement active learning strategies to identify and prioritize the most informative examples for further training.
- Safety and Security Testing:
- Red-Teaming: Employ ethical hackers to probe the system for vulnerabilities and potential misuse scenarios.
- Adversarial Testing: Subject the model to carefully crafted inputs designed to cause errors or unexpected behavior.
- Prompt Injection Testing: Evaluate the model’s resilience against malicious prompts aimed at bypassing safety measures.
- Privacy Preservation: Conduct differential privacy analyses to ensure individual data points cannot be reverse-engineered from model outputs.
- Robustness Testing: Assess the model’s performance under various stress conditions, including data drift and edge cases.
- Ethical AI Audits: Regularly review the model’s outputs and decision-making processes for alignment with ethical guidelines and societal values.
- Bias and Fairness Monitoring: Continuously evaluate the model’s outputs across different demographic groups to detect and mitigate unfair biases.
- Security Penetration Testing: Simulate cyber attacks to identify and address potential security vulnerabilities in the AI system’s infrastructure.
By incorporating these post-inferencing strategies, you can significantly enhance the performance, reliability, and adaptability of your AI model, ensuring it continues to meet user needs and expectations over time. You can also significantly enhance the robustness, reliability, and trustworthiness of your AI model. These practices help ensure that the model not only performs well but also operates safely and ethically in real-world scenarios.
Data Flow and Manipulation
Understanding how data flows through each stage of this design pattern is crucial for optimizing AI applications. The following diagram is an example of what a data flow might look like for a medical AI application:
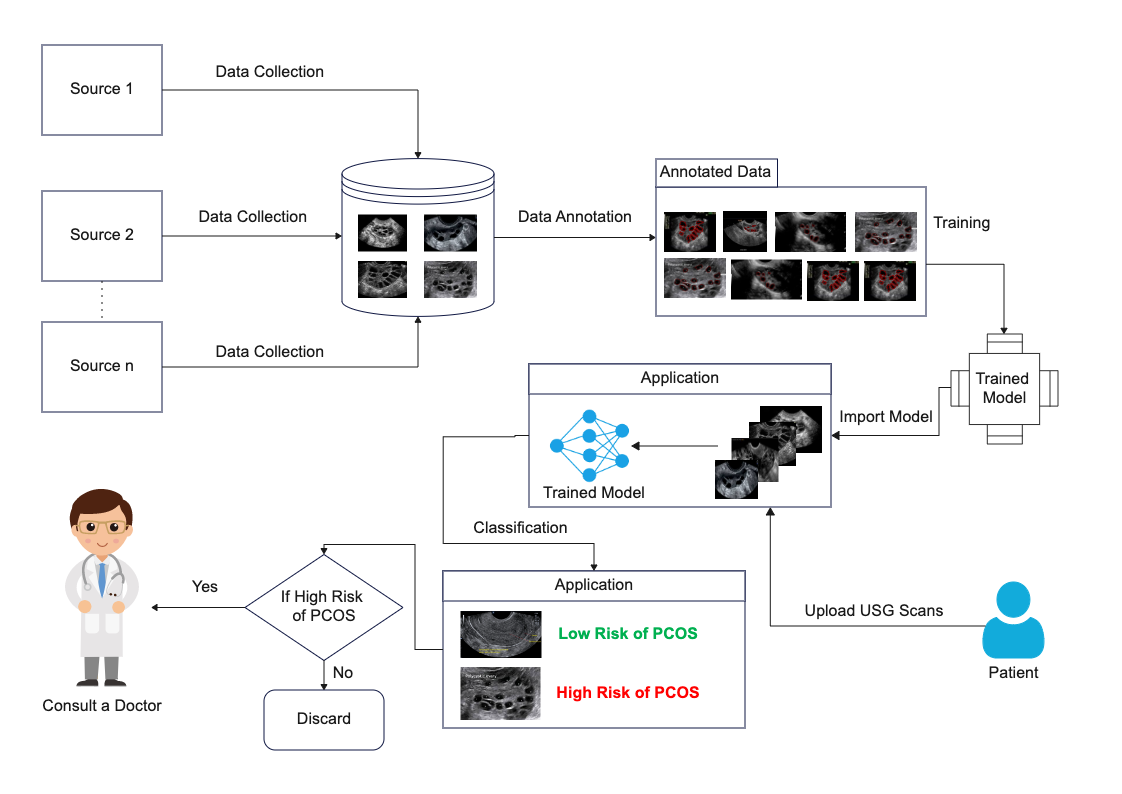
Optimization Strategies for Solutions Architects
Solutions architects play a pivotal role in optimizing AI workflows. Here are several strategies to enhance performance at each stage:
- Resource Allocation: Ensure that the infrastructure is capable of handling the computational demands of AI models, particularly during the training phase where resource use is highest.
- Cost Management: Monitor and optimize cloud resource usage, especially when deploying models in production. Utilizing serverless architectures can help manage costs effectively (Source: Addressing Scalability and Latency in AI).
- Scalability Strategies: Implement auto-scaling solutions to dynamically adjust resources based on demand, reducing latency and improving responsiveness during peak usage times.
- Latency Reduction: Use edge computing to process data closer to the source, minimizing latency associated with data transmission to centralized servers.
The AWS Well Architected Framework still provides a good analogous framework for the optimizing of AI architectures.
Real-World Examples
Several organizations have successfully implemented emergent AI architectures, demonstrating the effectiveness of these strategies:
-
IBM Watson in Healthcare: IBM Watson utilizes AI to analyze massive datasets in healthcare, assisting clinicians in making informed decisions and personalizing patient treatment plans. The successful deployment of Watson has led to improved patient outcomes and streamlined medical processes (Source: Real-World Applications of AI).
-
Coca-Cola’s AI-Driven Marketing Campaigns: By leveraging AI, Coca-Cola has enhanced customer engagement through personalized marketing strategies. The AI system analyzes customer data, allowing for targeted campaigns that have increased sales and brand loyalty.
Challenges in AI Application Development
Despite the advantages of AI architectures, several challenges persist:
-
Scalability: AI applications often require significant computational resources, which can lead to cost inefficiencies if not managed properly. Vendors may also experience difficulties scaling their applications dynamically in response to user demand. Solutions: Implementing auto-scaling solutions and leveraging serverless architectures can help manage resource allocation effectively.
-
Latency: Cold start latency in serverless environments and delays in data transmission can hinder performance, particularly for latency-sensitive applications. Solutions: Utilizing edge computing can dramatically reduce latency by processing data locally, while predictive auto-scaling can help anticipate demand spikes and adjust resources proactively.
Future Trends and Considerations
As AI technology continues to evolve, several trends are emerging:
-
Generative AI Integration: More organizations are adopting generative AI capabilities to enhance innovation and streamline processes, with 24% of organizations already integrating it across their business (Source: Emerging Trends in AI Architecture).
-
Data Modernization: Companies are prioritizing the modernization of their data architectures to support broader AI deployments, with legacy systems often inhibiting progress.
Experts predict that as AI continues to advance, we will see increased automation in data processing and decision-making, leading to more efficient workflows and innovative applications across various industries.
Conclusion
Understanding the emergent AI application architecture and the associated design patterns is essential for professionals in the field. By mastering the data flow and optimization strategies, software engineers and architects can build robust AI solutions that drive meaningful results. Key takeaways include the importance of data preparation, the need for continuous feedback, and the value of leveraging modern technologies for scalability and latency management. As we continue to explore the potential of AI, staying informed about emerging trends and challenges will be crucial for future success.